Road 2 NLP- Text Classfication文本分类模型(TextCNN)
Eajack Lau
7月 02, 2019
1. 参考资料
- TextCNN论文:《Convolutional Neural Networks for Sentence Classification》,作者Yoon Kim,纽约大学学生、哈佛大学研究生
- 博客文:《Implementing a CNN for Text Classification in TensorFlow – WildML》
2. TextCNN原理
TextCNN,由2014年Kim提出,该模型框架很简单。这篇文章算是较为出名的、关于CNN在NLP领域应用的开山之作。因为,在此之前,CNN在计算机视觉CV的图像分类等任务中应用广泛,而在NLP领域应用较少。思路引用了CNN在图像中的应用思路,将文本转化为矩阵(image)处理。
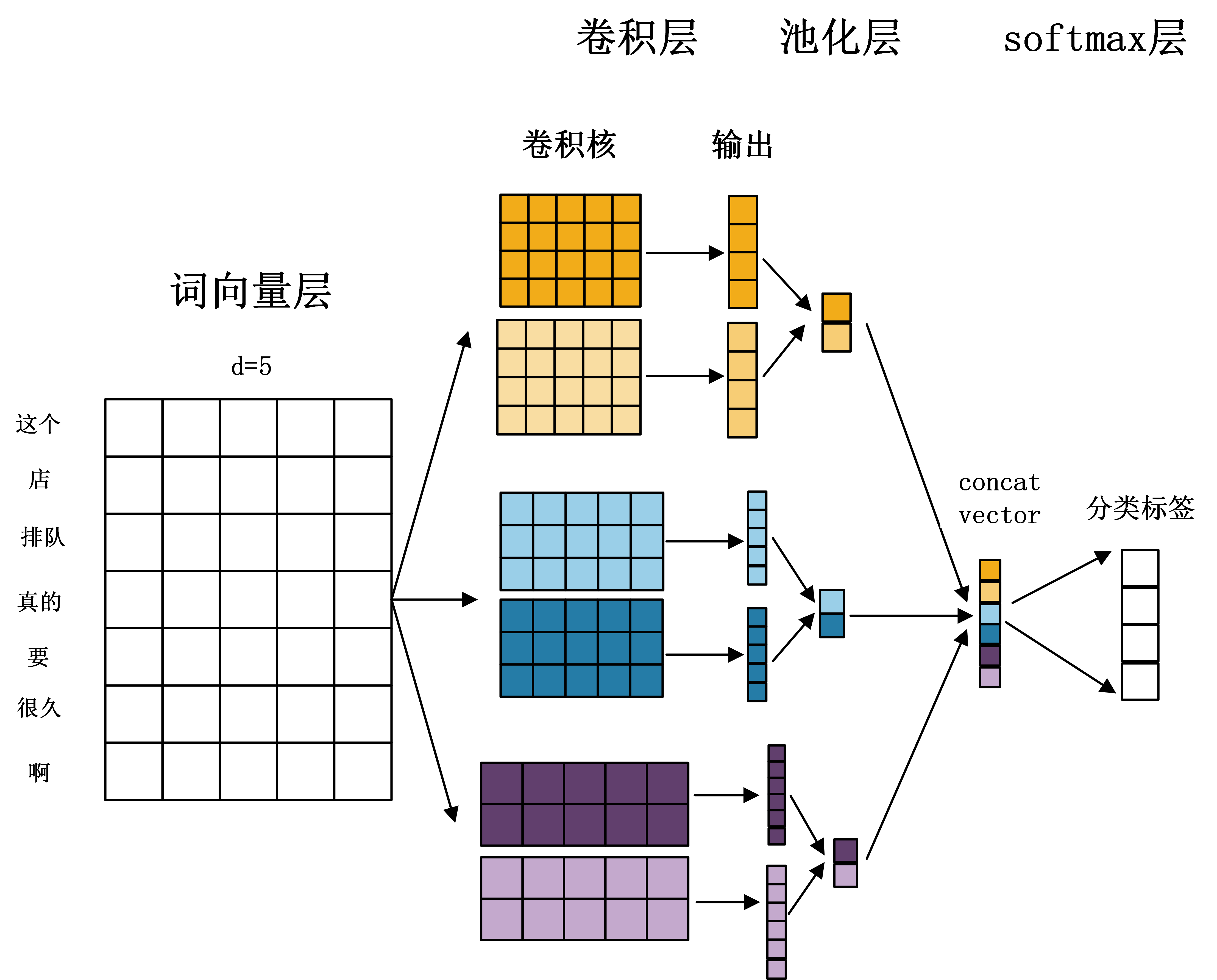
现分层介绍:
- 词向量层:TextCNN输入是词向量化后的分词文本,可取Word2vec、GloVe、FastText、ELMo或者多种concat组合等的词向量形式。以上图为例,文本
这个 店 排队 真的 要 很久 啊7个词语,即可对应7个词向量。此处假设词向量维度为d=5。所以文本可以等价为7*5的矩阵,其实和image矩阵一样了!!(这也是我第一次了解TextCNN感到的惊讶之处,CNN从CV到NLP的迁移很好) - 卷积层:n组卷积核,每组m个核,一般每组卷积核尺寸取连续自然数。如上图,n=3,m=2,尺寸为(2,3,4),即((2×d), (3×d), (4×d))的矩阵尺寸。卷积输出为n*m个向量。
- 池化层:1阶最大池化。遍历卷积层输出的n*m个向量,取最大值然后先每组内部concat,之后全部concat,组成concat vector。
- softmax层:对concat vector进行softmax处理,可二分类/多分类,得到预测分类标签$Y_{predict}$。同时,实际标签为$Y_{real}$,构造loss function,SGD等算法训练TextCNN模型参数。
特别地,当分词以字符形式分词,则为charCNN。即文本变成这 个 店 排 队 真 的 要 很 久 啊,直接按字分词,对应为字向量。